NBomber v6.0.1
· 7 min read



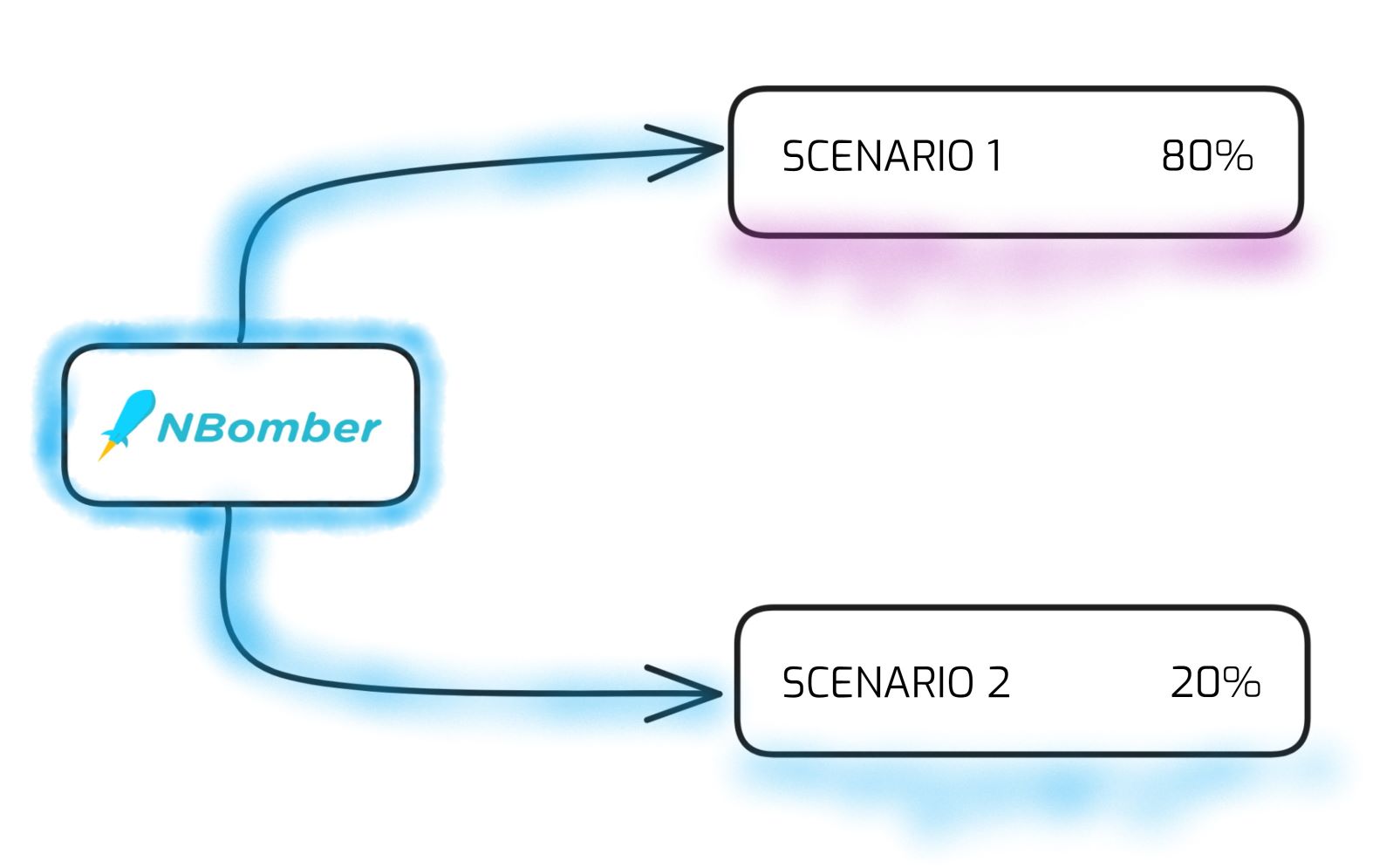
In the new release, we are introducing Custom Metrics, one of the most requested features. Additionally, we've made several improvements related to thresholds, memory consumption, CSV, HTML reports, and more.
Custom Metrics